Web Scraping is Changing
This article isn’t meant to discuss what web scraping is, or why it’s valuable to do. What I intend to focus on instead, is how modern web application architecture is changing how web scraping can/must be performed. A nice article discussing traditional web scraping just appeared in Hacker Newsletter #375 by Vinko Kodžoman. His article tipped my motivation to write this.
Traditional Scraping
Up until recently, data was typically harvested by parsing a site’s markup. Browser automation frameworks allowed this to be achieved in various ways, and I’ve used both Beautiful Soup and Selenium to achieve what I needed to in the past. Vinko discusses in his article another library lxml, which I’ve not tried. His explanation of lxml and how it interacts with the DOM is good enough to allow general understanding of the way scraping is performed. Essentially, your bot reads the markup, and categorizes relevant data for you.
Entering Front-End & REST APIs
Background
Modern web applications often implement some sort of front-end framework, such as Angular, React, Vue, etc. These JavaScript frameworks communicate to a web API of some sort to retrieve data. This means that multiple requests are required before the actual markup is built that contains useful data. Typically those requests require some sort of parameters to return only a subset of the data to you in the markup.
Problem
Earlier this year I was tasked with developing a scraper to collect data from a website which used Angular 2 on its front end. The requirement was that it collect business listings from each region on the site, however, the listings were only shown based on the boundaries of a Google Map frame users were able to drag around. There was no way to iterate the markup via pagination, and no directory/list of all existing regions. Traditional scraping of the markup wouldn’t work, because the content was rendered dynamically. I couldn’t figure out how to use BS4 for this task, and I was stumped.
Solution
I began to browse the site in question and examine the requests that it made via Postman. What I discovered was that life was much easier under this new type of web app architecture. AJAX calls were made via GET requests to return the data I was looking to collect. After spending a little time browsing the site to map the required endpoints of the REST API and their parameters, harvesting the data was substantially easier via their own API than it ever was in the days of parsing markup. Data was returned in JSON format, and could be added directly into a Mongo collection. Essentially, all the data could be copied from the website in a matter of half a minute or so.
Cool Story Bro, But Example?
What inspired me to write this article was a project at work. Since paperwork and money are involved, I can’t provide the examples I wish I could. However, here’s an example using a site in the Marijuana industry 😉
Example Scenario: You’re wanting to know every single place to buy marijuana in the country. Because you love marijuana!
First, browse Leafly.com (a place to find you some marijuana) and check out what’s going on in the background.
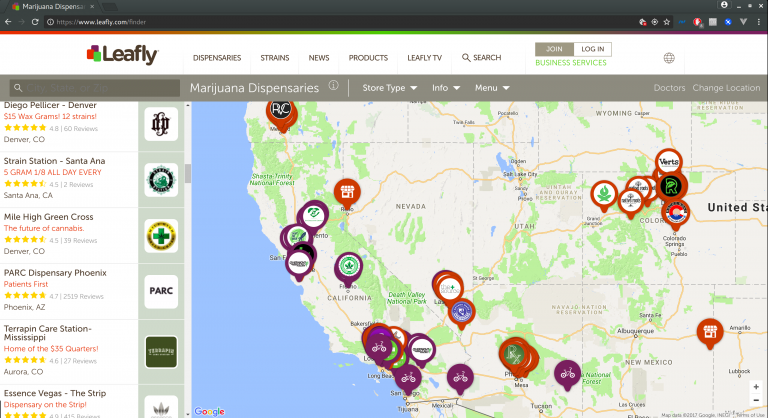
You can see a post request is made each time you change the map, and the request includes the top left and bottom right corners of the map frame.
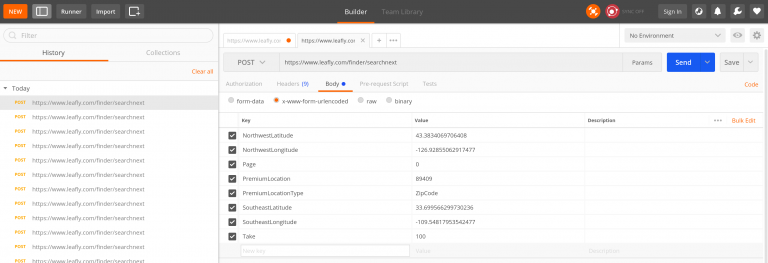
Here is a Python script to make a POST request to the API endpoints on Leafly with the parameters that we just discovered. We’ve ignored sending any headers at all, and set the “Take” parameter to be absurd.
import json
import requests
#from pymongo import MongoClient
class LeaflyHarvest(object):
"""
Leafly.com proof of concept data harvester.
"""
def scrape_dispensaries(self):
"""
Scrape all dispensaries from Leafly.com.
:return: void
"""
# API Endpoint to search for stuff on Leafly
url = "https://www.leafly.com/finder/searchnext"
# Body of the request
data = {
"NorthwestLatitude": 57.70487627437739,
"NorthwestLongitude": -138.49595341516113,
"Page": 0,
"PremiumLocation": 84720,
"PremiumLocationType": "ZipCode",
"SoutheastLatitude": 12.898819268131966,
"SoutheastLongitude": -33.027203415161125,
"Take": 9000
}
data = json.dumps(data)
# Endpoint's response to you
response = requests.post(url, data=data, headers={"Content-Type": "application/json"}).json()
# Within this loop you could filter/store data...
for dispensary in response["Results"]:
print(dispensary['Name'])
print(len(response["Results"]))
if __name__ == "__main__":
LeaflyHarvest().scrape_dispensaries()
The output will be something like:
.......
.......
Fullerton Flowers
New Generation
Sierra Vista Phytoceuticals
Hamilton Wellness Center
4038
If this wasn’t a proof of concept, you could do much better than this by adjusting the coordinates a few times and taking multiple samples. There are a lot things to change if you were trying to make a legitimate Leafly scraper, I know. I’m just demonstrating that the ability to grab over 4k listings in a few seconds is pretty neat.
Conclusion
It’s getting easier to scrape large amounts of data when front-end frameworks talk to API’s with no authentication, especially if they have no limit to the request size.
P.S. If you’re ethical you will obey the terms of service posted on any site. You’ll then determine that running the provided proof of concept is wrong (don’t do it).