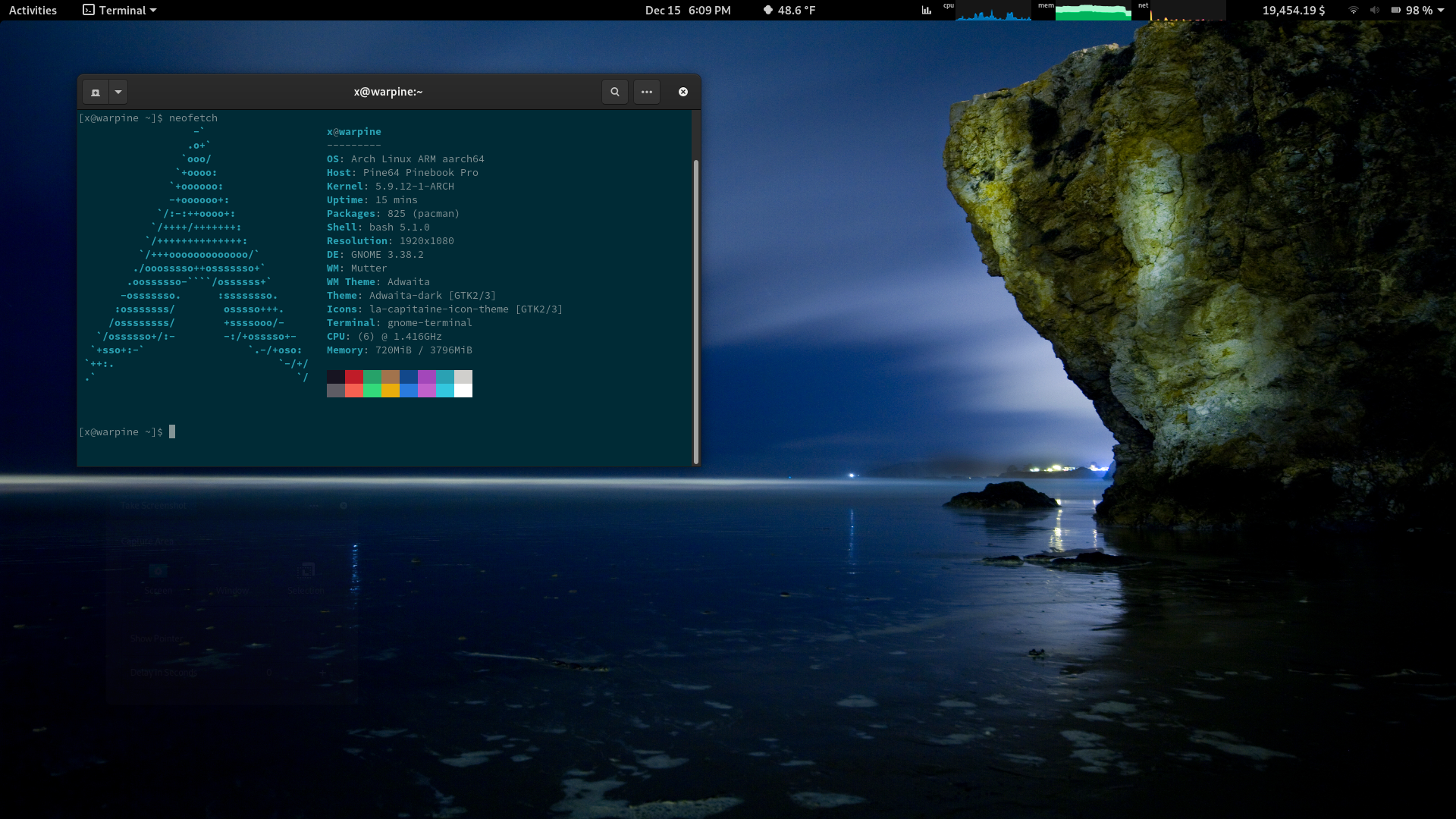
In my previous post I went through the steps I used to install Arch Linux on my Pinebook Pro with a LUKS encrypted root partition. It appears that the repositories used in that post have been retired, and the packages hosted at https://nhp.sh/pinebookpro/ are no longer there. A big thanks to Nadia Holmquist Pedersen for all the work she’s done for Arch on the Pinebook Pro.
The following instructions use Sven Kiljan’s project. You can find his blog post discussing it here, and the GitHub repository here.
My Pinebook Pro came in last week and yesterday I finally got a chance to really play with it. The first thing I wanted to do was get Arch installed on it with an encrypted root partition. I need these notes as a reference to use the next time I do this, so I figured I’d post them up to help anyone else out that may be trying to achieve the same thing. This post ignores post installation configuration. It just gets you booting into the terminal of your LUKS encrypted partition. From there it’s up to you to setup users, install your desktop manager, etc.
Traceback is an easy level box. It’s one of the first boxes on which I’ve been able to get user and root in one sitting. There’s a little bit of OSINT and guess work involved in the initial foothold, and the user/root portions aren’t too difficult at all. The theme of the box is that it has already been compromised by another hacker (Xh4H who authoried the box), and you seem to be retracing their steps while gaining user and root flags.
Traverxec is an easy box worth 20 points, hosted on 10.10.10.165. As we will see the name is indicative of the vulnerability we’ll leverage to gain our initial foothold. Despite having had difficulty with a few steps, when it’s all said and done the box is rather simple. This writeup is a short one because of that.
Information Gathering
As always, we’ll add the IP of the box to our /etc/hosts file. So, from here on out traverxec.htb points to 10.10.10.165.
For some time now, I’ve expected the introduction of new top level domains to confuse the general public. When users are confused, they’re more easily manipulated, making them more likely to fall for age old tricks like phishing attacks.
New gTLDs
It’s been almost 9 years since the announcement below from ICANN came out regarding new top level domains, meaning there would be many more options than the traditional .com, .org, .net, .biz, .gov, .edu, etc.